
The topic FLAMEHAVEN FileSearch: Why This RAG Engine Feels Different from the Usual Stack is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Posted on Apr 20
• Originally published at flamehaven.space
At this point, most developers have seen the familiar stack:
The interesting part is what happens after the diagram:
how much infrastructure the stack quietly demands, how much of the retrieval path is actually auditable, how much of the system is still mechanical rather than opaque, and how much operational tax the user is forced to absorb just to get a search engine running.
That is where FLAMEHAVEN FileSearch gets more interesting than the usual “another RAG repo” framing.
This is not a feature announcement. It is a technical look at what the project is actually doing differently.
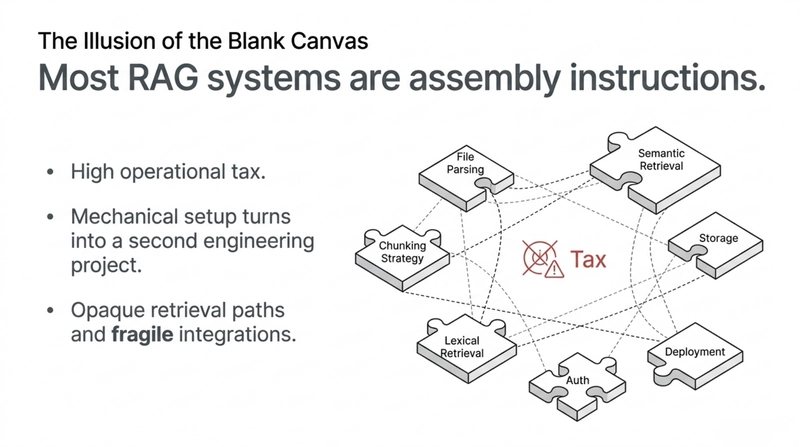
A lot of RAG systems are not products. They are assembly instructions.
They give you flexibility, but they also leave you responsible for stitching together:
It is less fine if what you actually want is a document search engine that can be deployed without turning the setup itself into a second project.
That is the first reason this repo feels different: it is trying to compress more of that surface area into one codebase.
A lot of RAG repos still behave as if semantic retrieval is the main event and lexical matching is an optional add-on.
That last point matters more than it sounds. The BM25 index is not eagerly rebuilt on every upload. It is marked dirty (_bm25_dirty) and rebuilt on first hybrid search after mutation. That is a very practical decision. It keeps ingestion cheaper without pretending indexing is free.
This is one of the deeper differences from many vector-first RAG demos: the system does not assume semantic retrieval should dominate exact-match behavior. It assumes production search needs both.
The second meaningful difference is the indexing granularity.
This repo introduces a KnowledgeAtom layer: a two-level indexing model with

Those chunk atoms are not anonymous fragments. They carry stable fragment URIs of the form:
The file-level object remains available, but the system can also retrieve chunk-level units directly. That reduces the usual gap between “the document matched” and “the relevant passage was actually isolated.”
The URI choice matters too. A lot of local-first search code still uses basename-style references that collide the moment two files share a name. This repo moves to a reversible, quoted absolute-path-based URI namespace (urllib.parse.quote(abs_path, safe=”)), which is much less fragile.
Another place where this codebase differs is that it does not outsource the core text pipeline by default.
Instead of treating chunking as a thin wrapper around an external library, it implements an internal text chunker with:
The chunking system is actually two-pass under the hood. The structure-aware TextChunker handles the document splits above. On top of that, KnowledgeAtom applies a second windowing pass when generating chunk embeddings — 800-character windows, 120-character overlap, and an 80-character minimum before a fragment is dropped. These two paths are separate by design: TextChunker is responsible for semantic structure, KnowledgeAtom for granular embedding units.
The engine also ships a ContextExtractor — a sliding-window utility that can enrich each chunk with text from its neighboring chunks before retrieval. It is fully tested, but it is not yet wired into the default ingestion path. It is available for downstream pipeline extension.
text
document
→ structure-aware split (TextChunker)
→ chunk atom embedding (KnowledgeAtom, 800-char windows)
→ multi-level indexing
→ retrieval
That is a better-shaped pipeline for document search than a naive chunk list.
This is probably the most unusual architectural choice in the repo.
Instead of anchoring everything around a heavyweight embedding model stack, the project uses Gravitas Vectorizer v2.0, a deterministic vectorization path built on:
The trade-off is obvious: this is not trying to win a leaderboard as a giant foundation-model embedding backend.
The point is that it makes the semantic path much cheaper to deploy, easier to reason about, and viable in environments where “just load another model” is operationally the wrong answer.
In other words, the semantic layer is being treated as infrastructure, not as a permanent excuse to expand infrastructure.
A lot of document search systems quietly assume one provider path.
First, it keeps the system from being hardwired to one hosted model assumption.
Second, it means the retrieval stack and the answer stack are not collapsed into the same dependency decision.
For non-Gemini providers, the code takes a provider-RAG route: local semantic retrieval first, then prompt construction, then model answer generation. That is a much more honest design than pretending all providers support the same retrieval semantics natively.
The local Ollama path is especially relevant. Not because “local” is fashionable, but because self-hosted document search is often most attractive precisely when data boundary control matters more than marginal model quality gains.
One of the easiest ways to tell whether a repo is becoming more operationally serious is to look at whether the core orchestrator is shrinking or swelling.
They do make the code easier to maintain without quietly reintroducing the same complexity elsewhere.
Documented performance figures (Docker, Apple M1, 500 PDFs ~2GB)
The cache-hit figure reflects the full path when semantic and lexical retrieval are served from warm indexes.
The cache-miss figure is dominated by the Gemini API round-trip, not local retrieval.
The performance story here is not just raw speed. It is that the repo achieves low-latency local retrieval by reducing dependency weight and simplifying the vector path, rather than by hiding heavy infrastructure behind abstraction.
It means the novelty premium is lower, and the real questions are clearer:
That is why a repo like this becomes more interesting now than it would have been in the most hype-saturated phase of the RAG wave.
When the field matures, the differentiator becomes whether the system removes real engineering burden.
If I had to reduce the repo’s technical distinctiveness to a short list, it would be this:
That is why this repo feels different from the usual RAG stack.
Because it makes several practical decisions that many RAG repos defer, externalize, or ignore.
There are also components that exist in the engine but are not yet connected to the default pipeline — ContextExtractor being the clearest example. The architecture is there; the wiring is not yet complete everywhere.
That is actually a good thing for a write-up like this, because it keeps the claim honest.
a repo with a real architectural point of view, a recognizably lower dependency burden, and code decisions that are meaningfully different from the usual vector-wrapper pattern.
That is a much stronger claim than vague “enterprise-grade RAG” language.
FLAMEHAVEN FileSearch is interesting because it is not merely trying to make retrieval work.
The more important question now is whether they reduce the actual engineering burden around RAG, or just rearrange it.
This repo is interesting because it appears to reduce some of it in code.
And in a field where many projects now converge into the same parser + vector store + model + wrapper pattern, that is a difference worth paying attention to.
GitHub: https://github.com/flamehaven01/Flamehaven-Filesearch
Templates let you quickly answer FAQs or store snippets for re-use.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
Thank you to our Diamond Sponsors for supporting the DEV Community
Google AI is the official AI Model and Platform Partner of DEV
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
We’re a place where coders share, stay up-to-date and grow their careers.



