
The topic Gemma 4: The Next Frontier in Open-Source AI for Developers is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
The story of open-source large language models has, until recently, been one of perpetual compromise. You could have capability or portability. You could have performance or privacy. Running a model that genuinely challenged proprietary offerings meant surrendering to cloud APIs, accepting opaque data-handling agreements, and building on infrastructure you neither owned nor controlled.
The release of Gemma 4 by Google DeepMind in April 2026 rewrites those trade-offs in a meaningful way. This isn’t just an incremental refresh. Gemma 4 represents a structural rethink — from its architecture to its licensing — that makes frontier-class AI genuinely accessible to software engineers who care about control, efficiency, and trust.
Since Gemma’s first generation launched, the community has downloaded models across the family over 400 million times, spawning more than 100,000 fine-tuned variants in the “Gemmaverse.” Gemma 4 is the answer to everything that community has been asking for next: better reasoning, multimodal input, on-device efficiency, and a commercially permissive license.
This article is a technical deep-dive aimed at practitioners — engineers who want to understand why this model family is architecturally significant, not just that it scored well on benchmarks.
Gemma 4 ships in four distinct configurations, each tuned for a specific tier of the hardware stack:
The “E” prefix on the small models stands for effective — these aren’t simply pruned versions of larger models. They are purpose-built for edge deployment in close collaboration with Google’s Pixel team and hardware partners including Qualcomm and MediaTek.
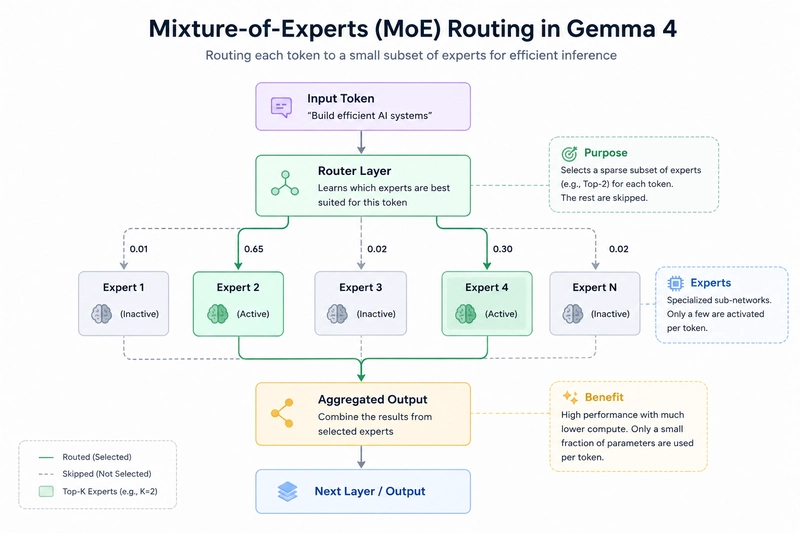
The 26B MoE variant is the headline architecture story for engineers who care about inference efficiency. The model contains 26 billion parameters total, but only 3.8 billion parameters activate per forward pass. This is the Mixture-of-Experts (MoE) paradigm in action: a learned routing layer selects a sparse subset of “expert” feed-forward networks for each token, rather than running the full network unconditionally.
The practical consequence is profound: you get approximately 97% of the dense 31B model’s MMLU Pro quality at roughly 12% of the dense FLOPs, according to the data Google DeepMind’s April 2026 technical report (Table 7). For production serving, this means dramatically better tokens-per-second throughput on the same hardware — the difference between a demo that works and a product that scales.
Both the dense and MoE variants use a carefully engineered alternating attention pattern: layers alternate between local sliding-window attention and global full-context attention in a 5:1 ratio. Sliding-window attention operates over 512 tokens on E-series models and 1,024 tokens on the larger variants.
This isn’t a novelty — Gemma 3 used the same pattern — but it’s extended here to serve the 256K context windows on the larger models. The key insight is that most token-to-token information transfer is local. Global attention layers handle the long-range dependencies, but you don’t need them on every layer. The result is inference that scales sub-quadratically with sequence length for most practical workloads.

Supporting 256K context without degradation is non-trivial. Naively scaling Rotary Position Embeddings (RoPE) produces a well-documented quality cliff beyond training lengths. Gemma 4 uses a dual RoPE strategy:
This combination lets the model generalize to long sequences without the quality degradation that plagued earlier long-context retrofits. For engineers building document-level reasoning applications, this is architecturally significant — not just a marketing claim.
The E2B and E4B models introduce Per-Layer Embeddings, an innovation carried forward from Gemma-3n. In a standard transformer, every token receives one embedding at input, and that same representation flows through all layers via the residual stream — forcing the embedding to front-load everything the model might eventually need.
PLE adds a parallel, lower-dimensional conditioning pathway. For each token, it produces a small dedicated vector per layer by combining a token-identity component with a context-aware projection of the main embeddings. This gives each layer access to a richer, context-sensitive signal without exploding parameter count — exactly the kind of efficiency innovation that makes small models punch above their weight class.
The 31B dense model reuses key-value tensors from earlier layers in its final six layers. This reduces memory bandwidth pressure during inference — a real constraint on consumer hardware — without meaningful quality loss. When running quantized models on RTX 3090/4090-class GPUs, this can meaningfully improve batch throughput.
All Gemma 4 variants accept text and image input, generating text output. The E2B and E4B models additionally support audio input natively.
All Gemma 4 models include configurable thinking modes — the ability to engage a chain-of-thought reasoning pass before producing a final response. This is triggered via a <|think|> token in the system prompt when using raw inference (Ollama and llama.cpp handle this transparently).
Alongside this, Gemma 4 ships with native function-calling support and native system prompt support — standard system, user, and assistant roles rather than the custom format required in earlier Gemma generations. For teams building agents, this means compatibility with existing scaffolding (LangChain, LlamaIndex, instructor) without adapter layers.
The model is released under an Apache 2.0 license — a commercially permissive open-source license that imposes no restrictions on commercial use, redistribution, or derivative works. This is the licensing that actually matters for production teams.
The fastest path to experimentation. Navigate to aistudio.google.com, select Gemma 4 from the model dropdown, and you have a full playground — chat interface, prompt tuning, and API key generation — with no local hardware required.
Kaggle hosts Gemma 4 weights and provides free GPU notebook environments. Ideal for researchers, students, and anyone who wants to run fine-tuning experiments without cloud billing.
For ML engineers who need raw weight access for fine-tuning, custom inference pipelines, or integration with existing training infrastructure.
Figure 1: The official Gemma 4 model card on Hugging Face. It highlights the model’s architecture (9.56B parameters), the permissive license, and the seamless integration with various deployment frameworks like Transformers, Ollama, and Google AI Studio.
The commercial and technical value of open weights is often underappreciated in benchmark-focused discussions. The practical implications are significant:
Benchmark comparisons across model families should always be read critically — numbers shift as evaluation methodology evolves, and different tasks favor different architectures. That said, the publicly available data as of April 2026 tells a coherent story.
Sources: Google DeepMind technical report (April 2026), Arena AI public leaderboard. Scores are approximate and dependent on evaluation methodology.
The honest conclusion: for teams that need multimodal capability, on-device portability, or the best intelligence-per-compute-dollar in the open-weight space, Gemma 4 is the current benchmark. For teams that need an established ecosystem of community fine-tunes and battle-tested production integrations, Llama 3’s head start remains relevant.
Let’s make this concrete. Consider the most common developer AI use case — a coding assistant — and examine why Gemma 4 is particularly well-suited for a private, local implementation.
Most coding assistant products today route your code through hosted APIs. When you’re working on proprietary business logic, unreleased product features, or security-sensitive infrastructure code, this creates a real dilemma: either accept the data-exposure risk or forgo the productivity gains.
Here’s a conceptual architecture for a privacy-preserving coding assistant using Gemma 4 E4B running locally via Ollama:
Several architectural properties make Gemma 4 specifically well-suited for this use case:
The release of Gemma 4 isn’t just an isolated model launch; it is a profound proof of concept for a new equilibrium in the AI landscape. It demonstrates a future where frontier-class reasoning capability is no longer synonymous with surrendering control over your data, your infrastructure, or your intellectual property.
Having spent significant time architecting this local assistant and testing the limits of Gemma 4, the sense of technical autonomy is transformative. We are moving away from an era where AI is a “black box” residing in a distant cloud, often acting as a bottleneck for privacy-conscious organizations.
From my perspective as a software engineer, transitioning to high-performance local models is a return to our roots: a state where you own the code, you own the model, and you maintain absolute sovereignty over your development environment. We are now at a point where a “digital polymath” can live entirely within your workstation, assisting with complex architectural refactoring while remaining safely behind a firewall you define.
The future of software development isn’t just about building larger models—it’s about building smarter, more private, and more integrated intelligence that empowers the developer without compromising the mission.
Templates let you quickly answer FAQs or store snippets for re-use.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
Thank you to our Diamond Sponsors for supporting the DEV Community
Google AI is the official AI Model and Platform Partner of DEV
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
We’re a place where coders share, stay up-to-date and grow their careers.



