
The topic Adding Gemma 4 speech recognition to a .NET desktop app: the llama-server sidecar… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
In April 2026 Google shipped Gemma 4, a multimodal model with a native audio path. I wanted to add it to Parlotype, my .NET 10 dictation app, as a second speech engine alongside Whisper. Four runtime paths got cut before I landed on llama.cpp’s llama-server as a child process. This post walks through the cuts, the architecture that survived, the variant catalog, and the benchmarks.
Parlotype is a voice-to-text desktop app for Windows with on-device speech recognition as the default. You hold a global hotkey, speak, release. Text appears in whatever app you were typing into. This post is about adding a second on-device engine. Cloud speech providers are a separate, opt-in track and not the subject here.
This is the long companion to my Gemma 4 Challenge submission on the same topic. The challenge post is the 5-variant tour with the shipping decision. This one is the runtime selection and the architecture under it.
Worth naming the constraints up front so the obvious answers make sense as dead-ends:
Then the trigger. Google released Gemma 4 (E2B and E4B) with a conformer audio encoder. Their reported WER on LibriSpeech-test-clean is 4.17%, which is competitive with bigger Whisper variants on clean speech. The same checkpoint can also do text post-processing later. The question was never “should we add Gemma 4”. It was “how, on Windows, in .NET, as another local engine that preserves the on-device default”.
This is the part of the post that took the most engineering and the part most worth writing down. Each rejection has a specific reason.
The obvious first stop. ONNX Runtime with the GenAI extension already runs Phi-3 and similar small models from .NET. If Gemma 4 were supported, the app would have nothing more than a new ISpeechRecognizer implementation. No extra processes, no separate installer.
It is not supported. Gemma 4’s architecture uses per-layer embeddings, variable head dimensions, and KV cache sharing. None of those were understood by onnxruntime-genai at the time of writing. Tracking issue: microsoft/onnxruntime-genai#2062.
Per-layer embeddings, briefly, mean each transformer layer has its own embedding matrix instead of sharing one. Variable head dimensions mean attention heads in different layers can have different sizes. Standard ONNX exporters and runtimes assume neither of these. Until ONNX Runtime ships the underlying support, no .NET-native path exists.
The second attempt was a small Python sidecar. Spawn a local FastAPI server, talk HTTP to 127.0.0.1, transcribe via HF Transformers with bitsandbytes for 4-bit quantization. From .NET: write a temp WAV, POST it, parse JSON, clean up.
This actually shipped, as a benchmark-only tool (ADR-024). It was never wired into the desktop app. Three reasons:
That third point is worth dwelling on. The first Gemma 4 benchmark on LibriSpeech-test-other came back at 96.94% WER. Peak host RAM for the sidecar process was about 79 MB, for a model that should occupy several gigabytes. The number was so bad that the obvious conclusion was not “Gemma 4 is bad”. It was “this pipeline is silently broken”. Two weeks later, on the same dataset and same machine, the llama.cpp path produced 13.15% WER for the same model.
The lesson is not “Python is bad”. The lesson is that the inference path you ship matters more than the model card claims, and you only learn that by measuring on your own stack.
The broken benchmark was also what prompted the search that found llama-server.
LLamaSharp is a native .NET P/Invoke layer over llama.cpp. More control, no separate process, no HTTP boundary. On paper this is the best fit for a .NET app.

The blocker was build-coupling. LLamaSharp links against a specific llama.cpp build at compile time. Switching the user’s backend from Vulkan to CUDA means rebuilding the host app. There is no good way to ship “use Vulkan on AMD, use CUDA on NVIDIA” from one binary. Audio support for Gemma 4 was also significantly more engineering than the chat-completions path.
Ollama would have given the smoothest UX of any option. It also did not support Gemma audio at the time. Tracking issue: ollama/ollama#15333.
Lemonade is strong on Ryzen AI hardware, but it is AMD-specific. Cross-vendor was a hard requirement.
llama-server is the HTTP server that ships with llama.cpp. At the decision date (2026-05-09, ADR-025), it was the only cross-vendor native Windows runtime with a stable HTTP API that supported Gemma 4 audio.
The cost is an extra process to manage. Cold start, port conflicts, crash handling, file locks during upgrade. Most of the rest of this post is how that was tamed.
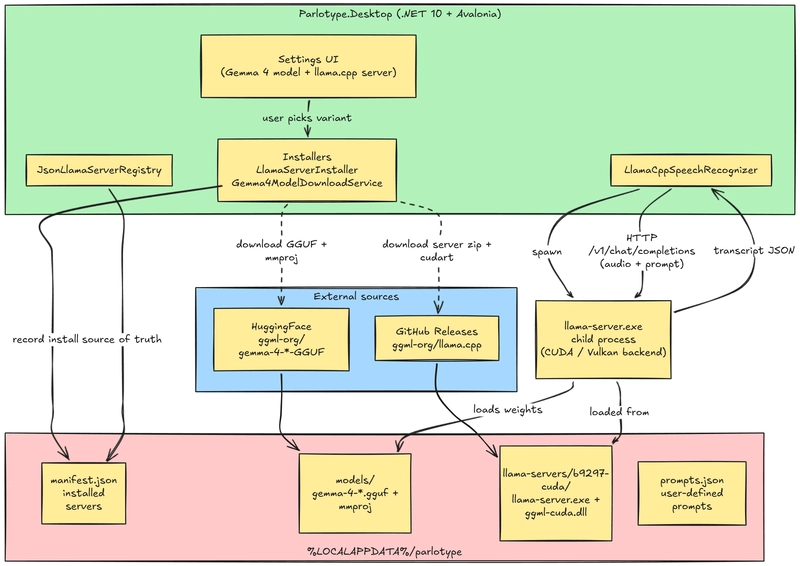
Two diagrams. The first shows what is on disk and who downloads what. The second shows where the audio pipeline branches by engine.
The diagram has three layers. The app (the .NET host process), disk (%LOCALAPPDATA%/parlotype for installed servers, models, and prompts), and external sources (HuggingFace for GGUFs, GitHub Releases for llama-server builds). The sidecar sits between the app and disk because it spans both: spawned by the app, but its binary and weights live on disk.
The diamond in the middle is the architectural pivot. DelegatingSpeechRecognizer reads the user’s SpeechEngine setting at init time and forwards every call to either WhisperSpeechRecognizer or LlamaCppSpeechRecognizer. The audio pipeline itself does not know which engine is active. Same capture, same VAD, same injector. The right branch crosses a process boundary, which is the cost of the Gemma 4 path.
Most “use llama.cpp from .NET” tutorials cover text-only chat. The audio path is worth showing in detail. Audio is sent as a base64-encoded WAV blob in an input_audio content block:
stream = false is deliberate. Simpler error handling, no SSE parser, and transcription is short-burst (under 30 seconds per clip, see trade-offs below). When post-processing lands and outputs longer text, streaming becomes worth the complexity.
Model size. GGUF E4B Q4_K_M is about 5.9 GiB. BF16 variants reach about 15 GiB. The Gemma4ModelInfo catalog (ADR-029) curates five variants and explicitly notes that ggml-org/gemma-4-E2B-it-GGUF does not publish a Q4_K_M asset. I learned this from a 404 in manual testing, then rebuilt the catalog from the actual file lists.
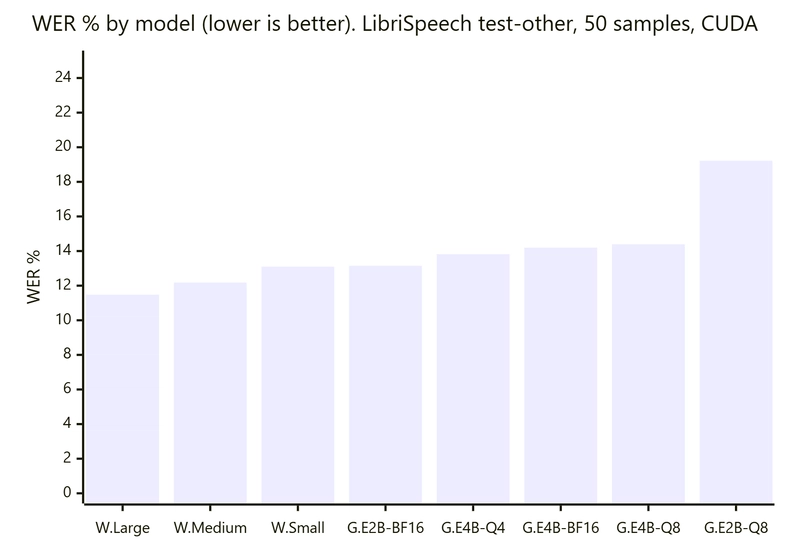
Noisy audio. On LibriSpeech-test-other, Whisper LargeV3Turbo on CUDA lands at 11.48% WER. The best Gemma 4 variant (E2B-it-BF16) lands at 13.15% WER. A 1.7-point gap on the harder English split. Google’s own evaluations showed Gemma 4 falling further behind on meeting-style noise (AMI is about 41% WER for Gemma versus about 16% for Whisper-large-v3). The honest pitch is that Gemma 4 is competitive on read speech and degrades faster than Whisper as noise and overlap rise.
Cold start. ADR-025 estimated 3 to 30 seconds for llama-server cold start. My first benchmark numbers confirmed the high end (21.3 seconds modelLoad for E2B-Q8_0). After I added an always-on warm-up pass (ADR-031), the same modelLoad dropped to 6.7 seconds. Most of the original cost was OS page cache and CUDA driver init, not the recognizer. Real InitializeAsync on a warm host is about 6.7 to 9.3 seconds for Gemma 4 and about 0.7 to 1.5 seconds for Whisper.
30-second clip limit. Gemma 4 audio is bounded at 30 seconds per request. Parlotype’s VAD already chunks below this, so it did not bite, but it is a real architectural ceiling.
E2B-Q8_0 is unstable. During the benchmark, gemma-4-E2B-it-Q8_0 intermittently emitted stray <|channel> reasoning tokens that crashed llama-server’s chat-template parser with HTTP 500. The first 50-sample run failed mid-stream. The second succeeded but with abnormally high RTF (0.315 versus about 0.04 for other Gemma quants) because of verbose thought-text bleed-through. The catalog keeps E2B-Q8_0 selectable for experimentation. The default is E4B Q4_K_M.
BF16 hallucinations on Blackwell GPUs. Separate from the E2B-Q8_0 issue, BF16 variants have a documented hallucination behavior on some NVIDIA Blackwell hardware. On the CUDA 13.1 box used here, BF16 was actually the strongest Gemma 4 variant, so this is hardware-specific.
The simplest “give the user a folder picker” version of this worked for about two weeks. Then it became obvious that:
ADR-026 added a full managed-install subsystem. A catalog backed by GitHub Releases with ETag caching. An installer that stages downloads under .staging/{guid}/payload/ and commits with a single Directory.Move. A registry (manifest.json) as the source of truth for what is installed. A tolerant asset parser that turns unknown backend strings into Unknown rather than throwing.
Atomic rename. Every install assembles under a staging directory and is committed by a single Directory.Move. A crash mid-install leaves no visible state. The user does not end up with a half-installed server. This is the kind of detail no library does for you.
Shared download primitive. StreamingFileDownloader was extracted from the pre-existing Whisper model downloader and is now used by both. About 150 lines, no abstraction layer, just a shared chunk loop.
The whole subsystem is about 1,800 lines across Core, Platform, and Desktop, plus tests. Worth naming so the cost is visible. “Add a button that downloads a binary” is not what shipped.
The Gemma 4 path sends a prompt alongside each audio clip. The text block in the user message tells the model what to do with the audio. Originally this was a hardcoded const. ADR-030 made it a first-class registry. Users create, edit, and duplicate prompts via the Settings UI. Prompts persist to prompts.json. The active prompt is re-read per transcription, no model reload required.
A {language} placeholder is the one small interface seam left for a future feature: source-language detection from keyboard layout. Small interface seams beat retroactive migrations of saved user data.
An example prompt to show what the multimodal-prompt approach actually unlocks.
Transcribe the speech verbatim. Then, on a new line, reformat it as a GitHub bug report with sections “Steps to reproduce”, “Expected”, “Actual”, “Environment”. If a section cannot be inferred from the speech, write (not specified).
Input (spoken): “I clicked save and the app just died, nothing in the logs, on my Windows machine, 64-bit.”
The main benchmark data is in results/comparison-libri-speech-test-other-2026-05-23-cuda.md in the repo. The numbers below match that file exactly.
The first time I ran these numbers, gemma-4-E2B-it-Q8_0 reported a 21.3-second modelLoad. The other Gemma variants reported about 9 seconds. Whisper Small reported 1.2. None of that matched my hand measurements. Once I added an always-on warm-up pass, the picture changed:
The decoder is greedy and deterministic, so WER and CER did not change between cold and warm runs. Only the timing fields became meaningful. If you publish inference timings without an explicit warm-up policy, you are publishing your filesystem cache state.
Before pivoting Whisper to CUDA, I ran the same three Whisper models on Vulkan. The result is almost invariant, but not quite.
Small and Medium produce bit-identical WER across runtimes. The greedy decoder is deterministic and the kernels reproduce. LargeV3Turbo regresses by 1.33 percentage points on CUDA, reproducibly.
The most likely culprit is non-bitwise-identical kernel math between the Vulkan and CUDA backends. Matmul and softmax reduction order, and FP16 accumulation order, are not guaranteed to be deterministic across GPU backends. At the scale of LargeV3Turbo’s larger matrices, accumulated FP error tips a handful of borderline decoder choices.
The takeaway is not “CUDA is buggy”. It is that GPU backends are not interchangeable when you care about exact transcripts. If LargeV3Turbo is your production target, benchmark on the runtime you will actually ship.
CUDA also delivered what you would expect on the other dimensions. RTF improved 8 to 26% across all three Whisper models. Host RAM dropped 30 to 60% because weights now live in VRAM. The speed and memory wins are real and worth taking.
A LlamaServerHost extraction. Right now LlamaCppSpeechRecognizer owns the llama-server process. The first post-processing consumer will need to share the server. A dedicated host class will manage spawn and terminate so neither workload can tear the server down on the other.
A post-processing pipeline. Same loaded model, second invocation. Whisper text -> llama-server -> cleaned, translated, or structured text -> injector. The configurable prompts feature is the first half of this. The consumer is what is still missing.
Source language detection from keyboard layout. The {language} token in PromptTemplate.Render is already in place. The detector is what comes next.
Windows only for now. .NET 10, MIT licensed. Pick Gemma 4 in Settings -> Speech Engine. The in-app installer downloads llama-server and the GGUF for you.
If you have shipped llama.cpp’s /v1/chat/completions audio path in production, I am curious about cold-start mitigations beyond keeping the server warm. Spinning-disk first-inference times in the 30-second range are the part I have not solved cleanly yet.
Maksim Demin is a .NET engineer building Parlotype, a voice-to-text desktop app. He writes about cross-platform .NET, Avalonia, and local AI.
Templates let you quickly answer FAQs or store snippets for re-use.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
Thank you to our Diamond Sponsors for supporting the DEV Community
Google AI is the official AI Model and Platform Partner of DEV
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
We’re a place where coders share, stay up-to-date and grow their careers.



