The topic Reviewing AI-Generated Code: Check Boundaries Before Logic is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Posted on May 3
• Originally published at elpic.Medium
Post 2 gave you structured prompts that produce better AI output. But “better” isn’t “perfect.” Even a well-constrained prompt will occasionally slip a database call into an application service, or sneak a business rule into a route handler. You still have to review the diff.
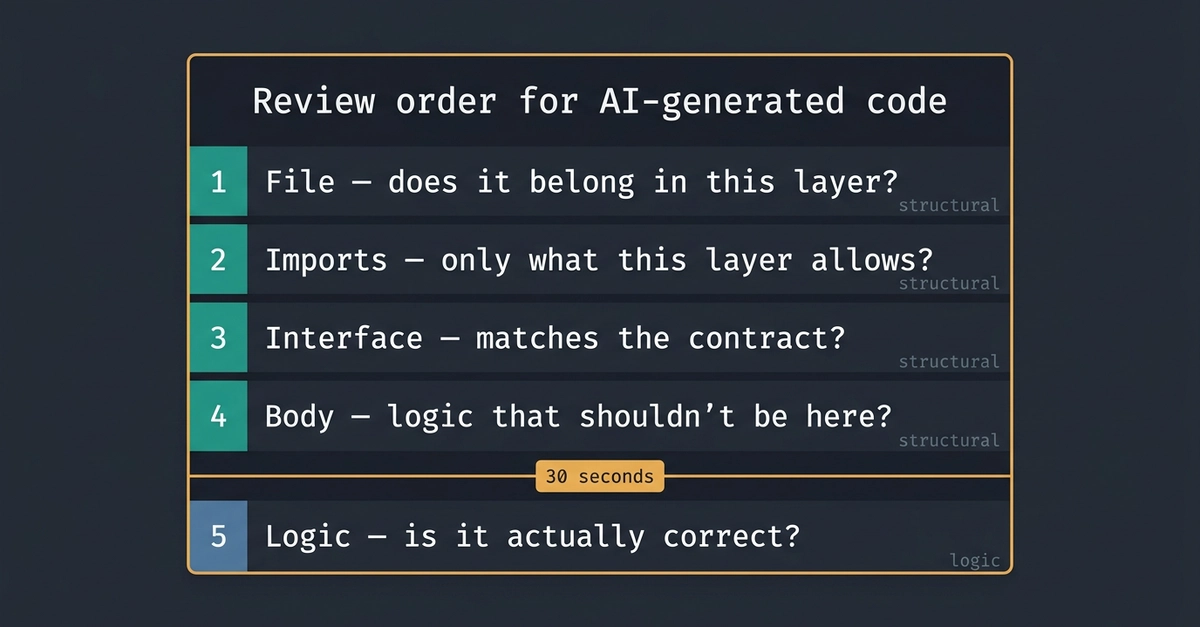
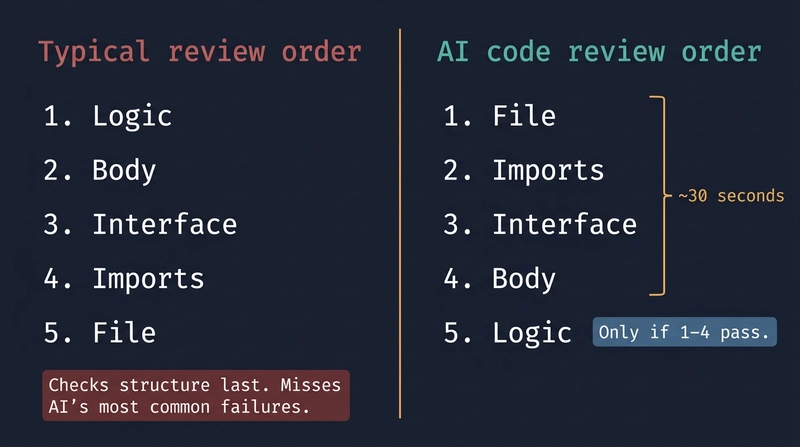
Reviewing AI-generated code the same way you’d review a colleague’s PR is slow, frustrating, and misses the real failures. Here’s a workflow that’s actually fast and checks the right things first.
When a colleague sends you a PR, you can ask them questions. You can understand their intent.
With AI output, you can’t. The AI made decisions about where code lives, what it imports, how it structures logic based on pattern-matching from its context window. It had no architectural intent. It was optimizing for “generates code that compiles and passes the tests I can see.”
With a colleague’s code, you’re asking: Does this solve the problem correctly?
With AI-generated code, you need to ask that but first: Does this code belong where it landed?
Logic bugs are easy to find. Boundary violations are quiet. A function that calculates the wrong total will fail a test. A business rule in the wrong layer will pass all the tests you wrote alongside it and only surface as a problem when you try to change something six months later.

Steps 1-4 take about 30 seconds combined. Step 5 can take minutes. If the code fails steps 1-4, the logic review is wasted you’re regenerating anyway.
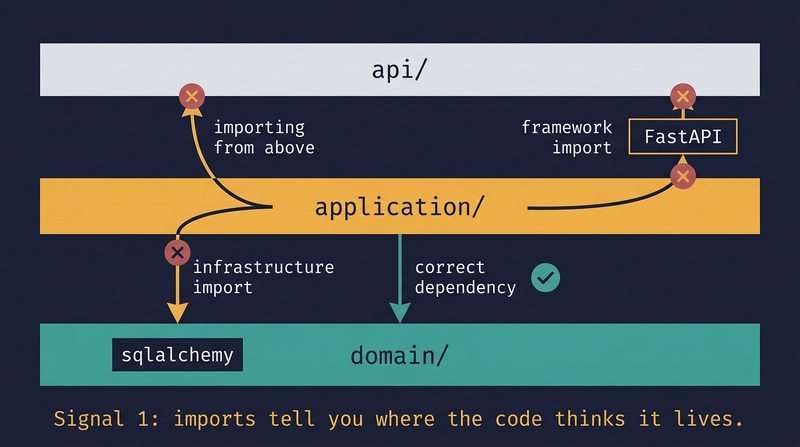
Look at the import block. Does this file import from a layer it shouldn’t depend on?
None of these cause a runtime error. The code works. But now you can’t test the service without a database session, and you can’t reuse it outside FastAPI.
What to do: Scan the first 10 lines. Wrong import? Stop. Don’t review the logic. Ask the AI to regenerate with the explicit constraint.
The AI puts logic wherever it fits syntactically. Here’s a loyalty points check that shouldn’t be in the route:
That condition “must have at least 100 points” is a business rule. When it changes, you’ll find it in the route handler, not the domain. And if you added a mobile API endpoint last week, there’s a copy there too.
What to do: Look for conditionals in route handlers that involve domain concepts. If the condition only makes sense when you understand the business domain not just the HTTP request it’s in the wrong place.
The AI introduces a new pattern that doesn’t exist anywhere else in your codebase:
Locally clean. But now you have a pattern that needs to be understood, maintained, and either adopted everywhere or deleted. The AI introduced it because it was convenient not because it fits your codebase’s patterns.
What to do: Ask: “Does anything else in this codebase do this?” If the answer is no, consider simplifying. Not always wrong but it should be a conscious choice.
The mutating version passes every test the AI wrote alongside it. It fails the immutability test but only if you wrote that test before reviewing the code.
What to do: For any domain method the prompt said should be “pure”, check the return statement. Returns self → mutating. Creates a new instance → pure. Five-second check.
When find_by_id() returns None, this crashes with an AttributeError. The correct behavior is raise KeyError(customer_id) so the route handler can return a 404. The AI wrote the happy path and left the error case unhandled.
What to do: For every data fetch in a service method, ask: “What happens if this returns nothing?” The answer should be raise KeyError(id). If it’s not there, add it.
Signal 1 check: db: Session = Depends(get_db) route is importing the database session directly. Infrastructure in the API layer.
Stop. You don’t need to read the rest. Send a corrected prompt:
Five-signal check on the second version: passes all five. Now review the logic. Two minutes total.
Rubber-stamping: Accepting AI output without running the structural check because “it looks fine”. The imports are at the top where you’d skip them. The logic reads correctly. The tests pass. Six weeks later you’re finding copied loyalty logic across three route handlers. The five-signal check takes 30 seconds. Do it every time.
Over-scrutinizing style: Spending 10 minutes debating whether the AI should have used a dataclass or a TypedDict for the return type. Style matters in final polish. The first-pass question is: is this code in the right place doing the right job? Note style issues, move on, address them in a cleanup pass.
After a few weeks of this workflow, something shifts. You stop bracing for surprise. You have a systematic check five signals, 30 seconds. Either it passes or it doesn’t.
You also start calibrating your prompts based on what slips through. If Signal 2 keeps flagging logic in route handlers, your prompts for that type of feature need better negative constraints. If Signal 1 keeps catching wrong imports in application services, your architectural context block needs a stronger rule.
The review and the prompting are a feedback loop. Each failed review tells you what to add to the next prompt.
Templates let you quickly answer FAQs or store snippets for re-use.
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment’s permalink.
For further actions, you may consider blocking this person and/or reporting abuse
Thank you to our Diamond Sponsors for supporting the DEV Community
Google AI is the official AI Model and Platform Partner of DEV
DEV Community — A space to discuss and keep up software development and manage your software career
Built on Forem — the open source software that powers DEV and other inclusive communities.
We’re a place where coders share, stay up-to-date and grow their careers.



